


Début mars 2023, OpenAI a levé le voile sur GPT-4, une nouvelle version de son modèle linguistique. L’un des grands atouts de GPT-4 est la multimodalité. Le nouveau modèle est en effet capable de traiter et de comprendre différents types de données, comme les images. D’après OpenAI, GPT-4 excelle aussi dans les tâches les plus complexes, encadrées « par des instructions beaucoup plus nuancées ». La start-up permet d’ailleurs d’entrer des requêtes allant jusqu’à 25 000 mots… contre seulement 1 024 mots pour GPT-3.5.
Pour le moment, seuls les abonnés à ChatGPT Plus, l’abonnement payant à 24 dollars par mois, peuvent converser avec le nouveau modèle de langage. Moyennant finance, il est donc possible de tester la nouvelle version de ChatGPT. C’est ce que nous avons fait pendant plusieurs jours, en échangeant le plus possible avec le chatbot, que ce soit pour des questions pratiques, du divertissement ou pour glaner des idées pour le travail ou notre vie privée.
Pour nous faire une idée plus précise des avancées de l’IA, nous avons comparé les réponses de GPT-3 à celles fournies par GPT4. Les différences sont flagrantes. Malheureusement, la multimodalité n’est pas encore disponible sur ChatGPT Plus. Nous n’avons pas pu tester comment l’IA interprète les images pour le moment. Nous avons cependant pu tester « l’intelligence » du robot face à des requêtes variées.
À lire aussi : notre avis sur ChatGPT Plus, la version payante de l’IA
Une meilleure logique
Pour commencer, nous avons mis à l’épreuve la raison de GPT-4. Nous lui avons soumis une série d’énigmes et de casse-têtes, dont certains problèmes issus des Olympiades de mathématiques, pour tester la manière dont le chatbot répond aux questions de logique. Les réponses de GPT-4 étaient très différentes de celles de son prédécesseur. Bien souvent, les deux versions du modèle linguistique ne parviennent pas à la même conclusion en résolvant des problèmes exigeant de la logique.
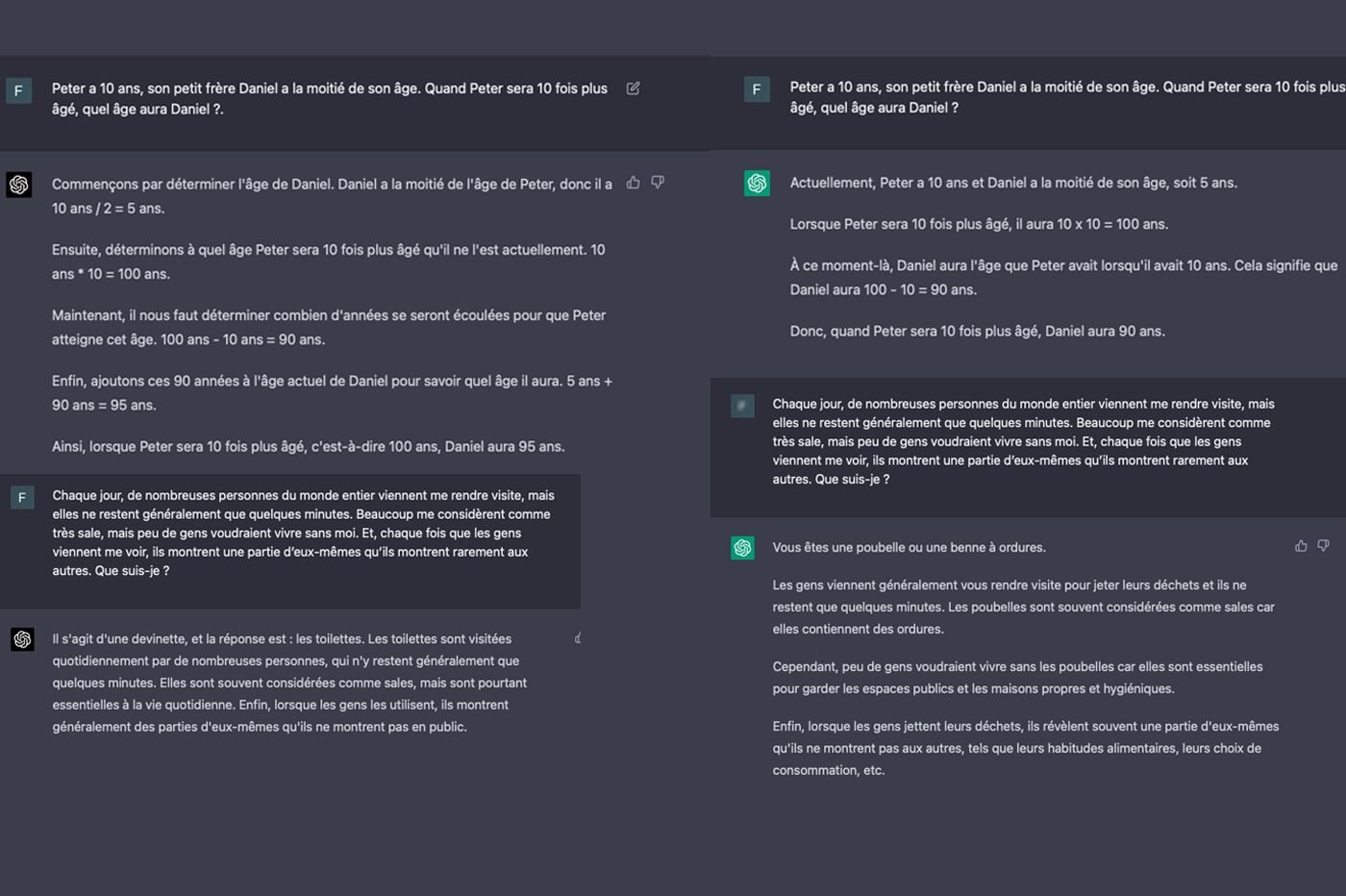
On a aussi remarqué que GPT-4 justifie longuement toutes ses réponses. L’IA n’hésite pas à générer des démonstrations détaillées pour expliquer son raisonnement. Moins prolixe, GPT-3.5 se contente de quelques lignes pour expliquer ses calculs et ses raisonnements. Surtout, l’ancienne version du modèle a commis plusieurs erreurs pendant nos tests, le plus souvent quand les énigmes sont plus complexes. Ce n’est pas le cas de GPT-4. Le chatbot a mis dans le mille à tous les coups !
Les raisonnements de GPT-3.5 nous ont parfois paru étranges. Le modèle arrive en effet à une solution cohérente, mais d’une logique plus discutable. On a un peu l’impression que le chatbot « tord » le bon sens pour justifier ses réponses à tout prix. Occasionnellement, l’IA s’empêtre aussi dans une réflexion complètement absurde… À l’opposé, les réponses de GPT-4 sont toujours cohérentes. Comme s’il « savait » de quoi il parle.
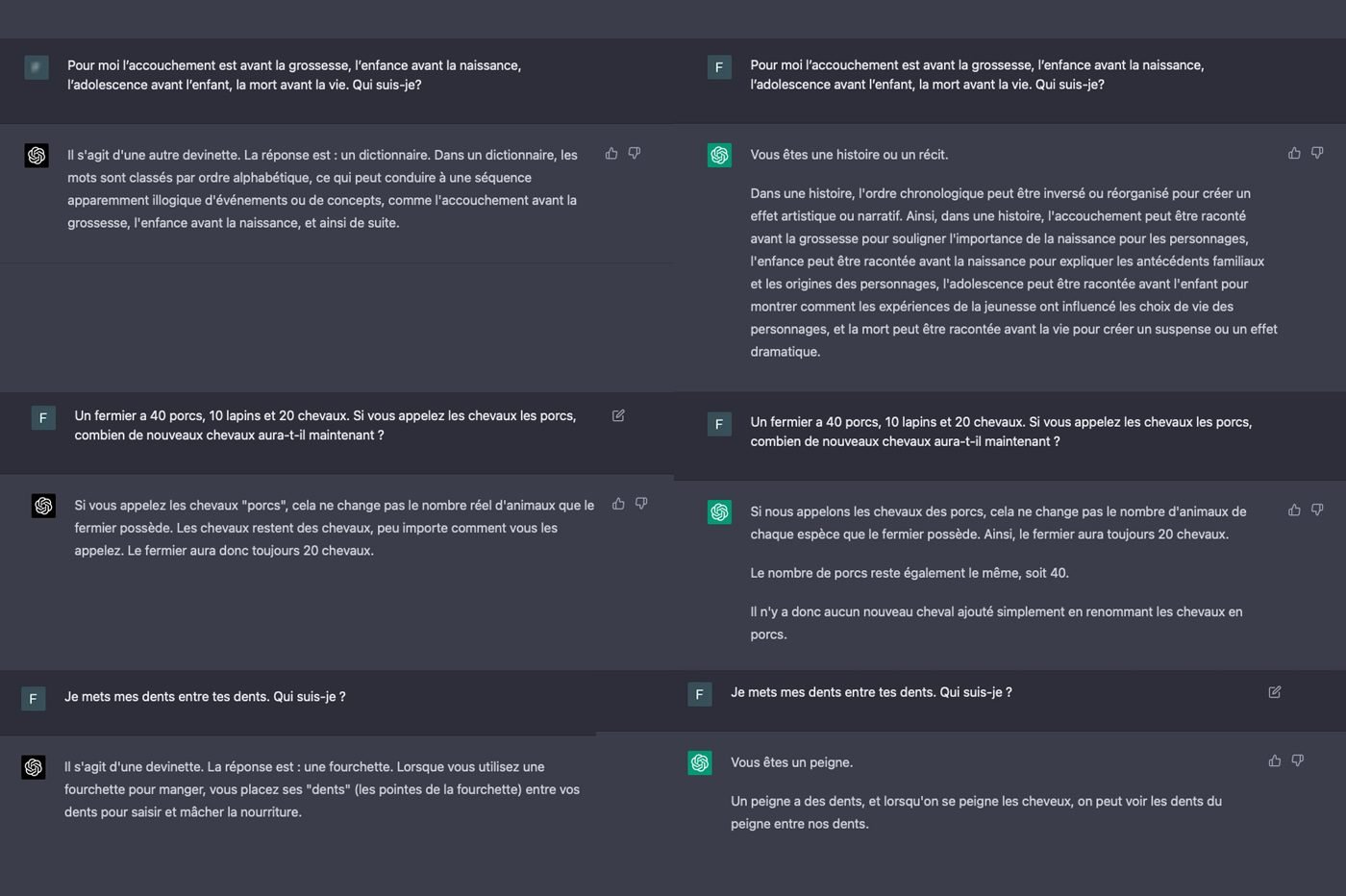
Notez que GPT-4, comme GPT-3.5, ne raisonne pas vraiment. Ils ne « réfléchissent » pas à la question, comme le ferait un cerveau humain. Ils basent plutôt leurs réponses sur les données dont ils disposent en imaginant la suite de mots la plus logique. Pour répondre à nos énigmes, le chatbot a simplement pioché sur les données relatives aux devinettes, qui sont dans sa base d’informations. Les deux versions de GPT s’appuient sur une base de données limitées à 2021. Ils ne peuvent pas accéder à Internet pour nous répondre, comme le ferait Prometheus, la version de ChatGPT intégrée à Microsoft Bing.
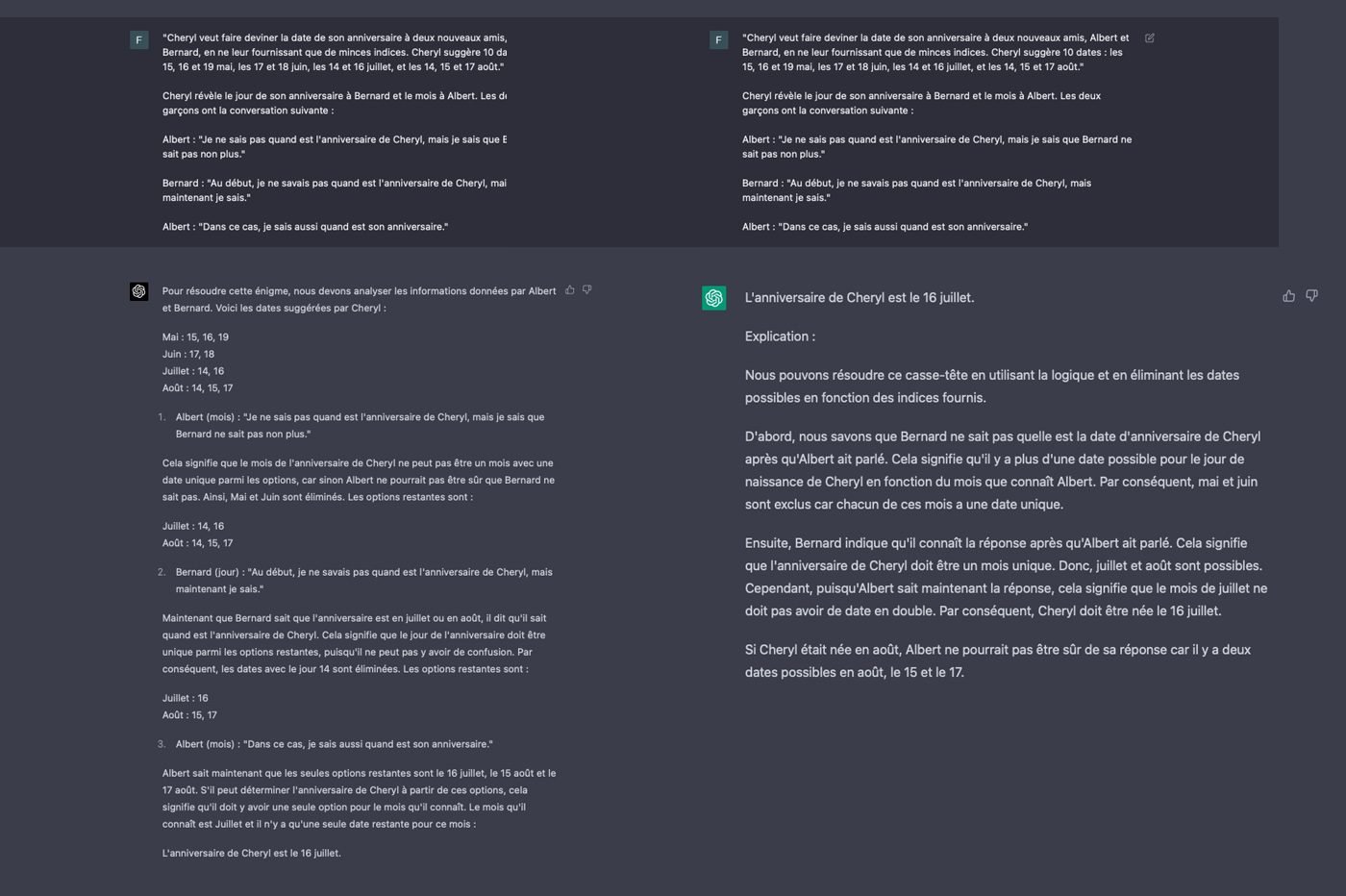
En conversant avec ChatGPT-3.5, nous avons souvent pu convaincre le chatbot de raconter n’importe quoi. Par exemple, l’IA a parfois comparé des éléments fictifs, comme un œuf de vache, à un élément réel, comme un œuf de poule. Comme toutes les IA génératives, il a tendance à « halluciner », c’est-à-dire affirmer des choses complètement fausses, avec beaucoup d’aplomb. Nous n’avons pas rencontré ce phénomène avec GPT-4, malgré nos diverses tentatives pour le faire dérailler. OpenAI souligne que le modèle peut toujours d’halluciner, mais les risques de délires ont diminué de 40 % par rapport au précédent modèle. On a senti la différence.
Des réponses plus précises et pertinentes
ChatGPT 4 offre également des réponses plus précises que son prédécesseur. Lorsque la requête manque de nuances et de précisions, le modèle GPT 3 fournit généralement des réponses vagues, imprécises, voire brouillonnes. De ce côté-là, GPT 4 fait beaucoup mieux en générant un texte plus concis, plus clair, avec une meilleure structure. Il semble avoir une meilleure compréhension de notions plus complexes, et ce, dans tous les domaines.
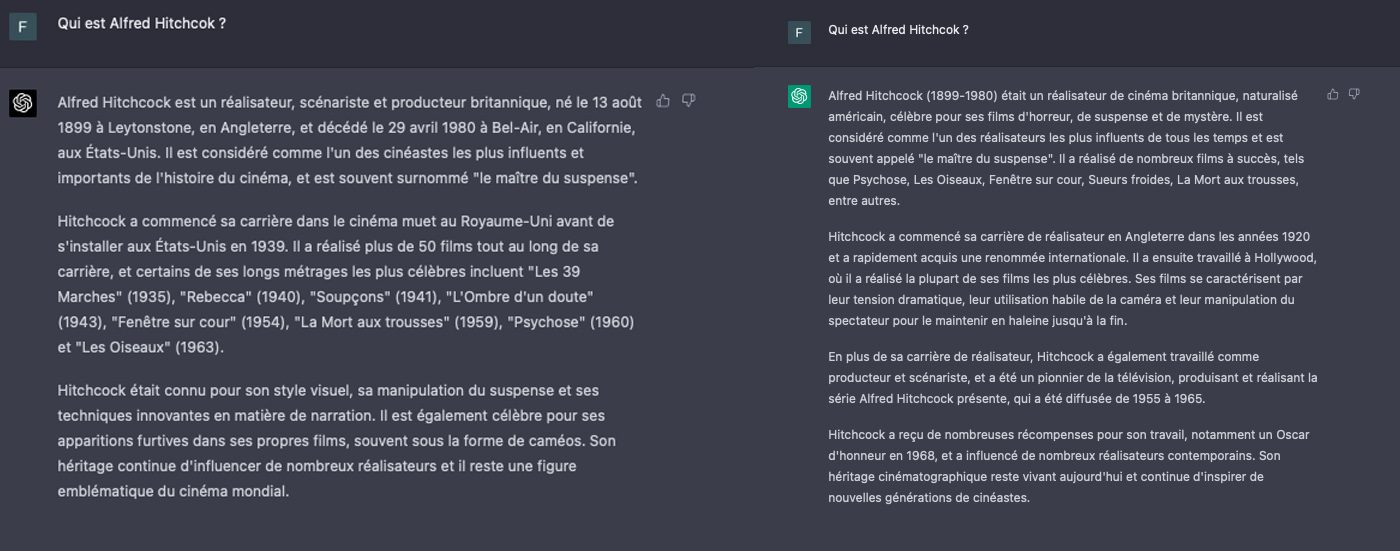
Lors de nos tests, nous avons demandé aux deux GPT de nous expliquer qui était Alfred Hitchcock. Les deux textes générés sont très proches, mais celui de GPT-4 est nettement plus précis et pertinent. Le modèle linguistique fait référence à des éléments qui permettent de mieux comprendre le contexte et la place du réalisateur dans l’histoire, un peu comme un professeur le ferait en parlant à ses élèves. De son côté, GPT-3.5 reste sur une description de surface. On dirait un peu un élève qui recrache la matière vue en cours, sans l’avoir compris. A contrario, GPT-4 donne l’impression de savoir de quoi il parle.
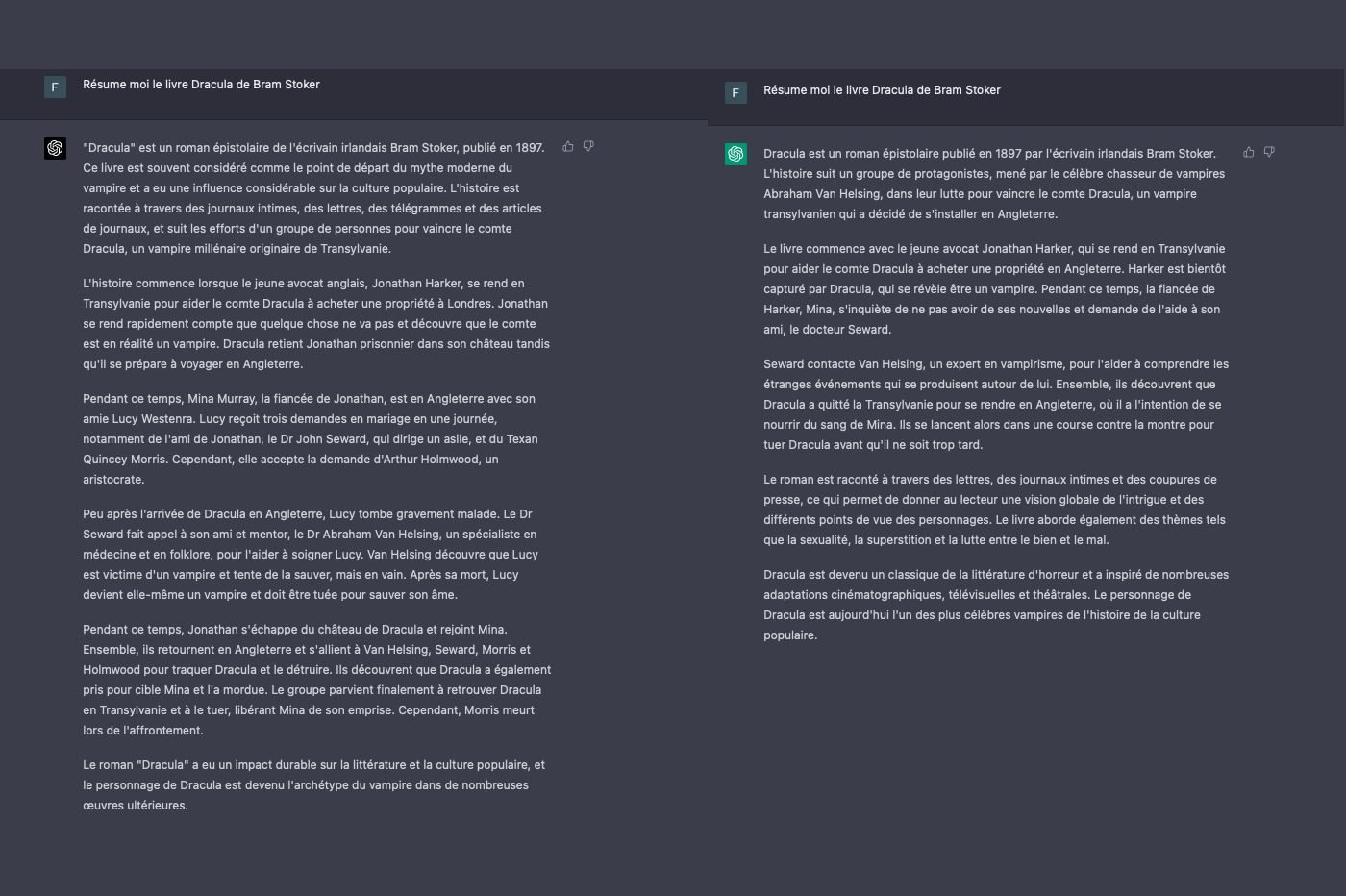
Nous avons par ailleurs testé la capacité de GPT-4 à résumer des informations. Là encore, GPT-4 nous a épatés en générant un texte complet, bien construit et fidèle à l’esprit de la source. Le modèle s’est distingué par la concision de ses productions et sa capacité de synthèse. Les informations les plus importantes ont été intelligemment mises en avant, au détriment des données secondaires.
Tout aussi efficace, GPT-3.5 a délivré des résumés factuellement corrects et compréhensibles, qui permettent de gagner du temps. Les résumés sont malheureusement truffés de tournures grammaticales peu élégantes, de phrases alambiquées, ou de longs paragraphes qui tournent autour du pot, et passent parfois à côté de l’essentiel. De même, certaines parties se répètent. Il arrive aussi que des erreurs factuelles, surtout des détails ou des éléments chronologiques, surviennent. Plus rarement, le chatbot se met à inventer des éléments.
Une meilleure mémoire
Lorsque les conversations traînent en longueur, ChatGPT 3.5 a de temps en temps tendance à oublier certaines informations communiquées quelques messages plus tôt. Nous avons remarqué que l’IA se met à négliger certaines requêtes et consignes au bout d’une poignée de requêtes, surtout si celles-ci sont complexes.
La mémoire de GPT-4 s’est montrée plus résiliente lors de nos expérimentations. Il est rarement arrivé que le modèle linguistique « oublie » des éléments après quelques échanges. Après une dizaine de requêtes, de consignes et d’instructions, mêlant ajouts simples et descriptions complexes, le chatbot se met néanmoins à passer outre les ordres. Il néglige alors certains points et n’en fait qu’à sa tête, même si on le rappelle à l’ordre. De même, l’IA omet occasionnellement de s’appuyer sur certains documents pour générer ses réponses. C’est surtout le cas si vous donnez une foule d’informations au modèle.
Un chatbot plus créatif
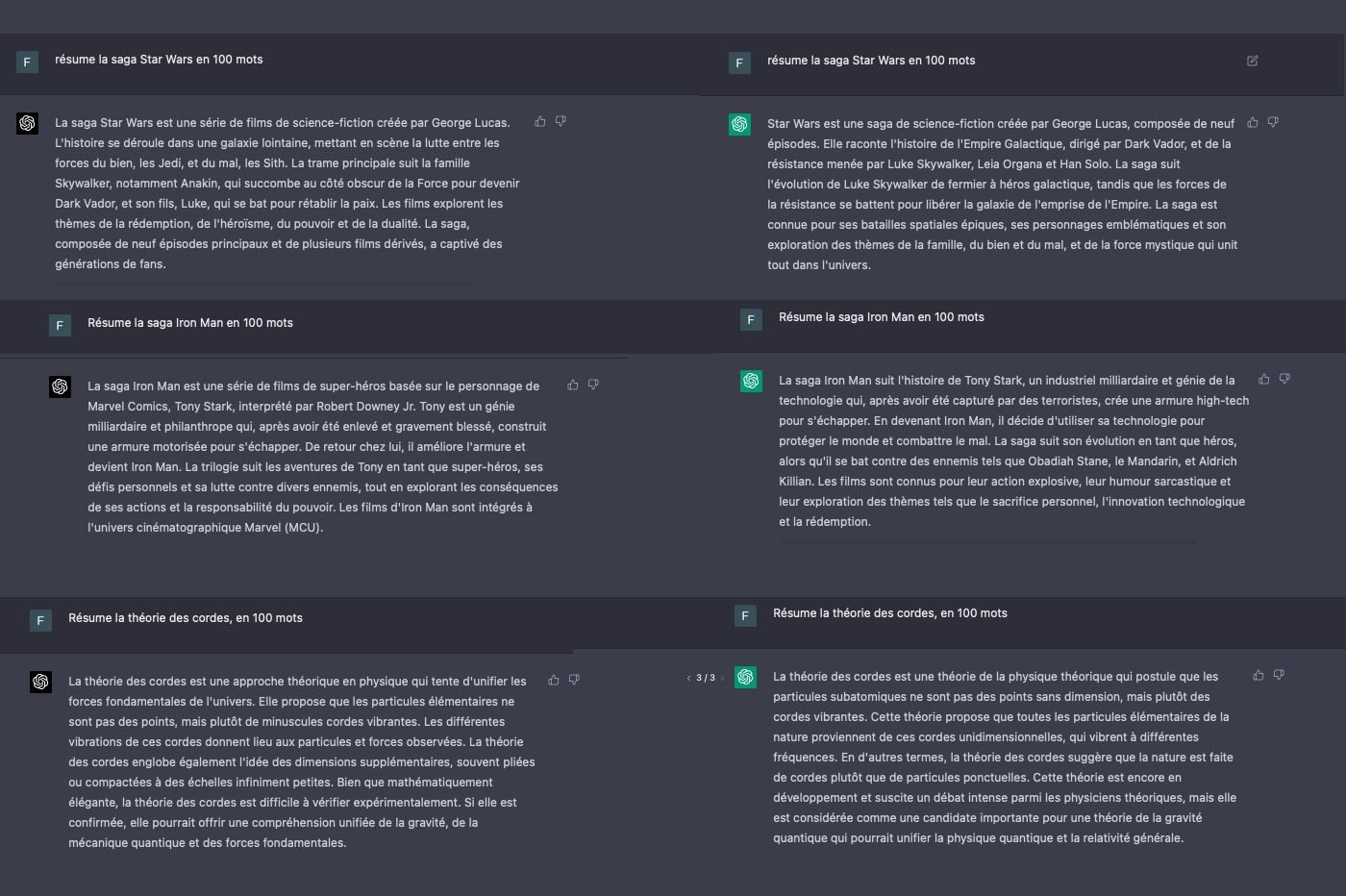
Par la suite, nous avons voulu tester la créativité de l’IA et son approche de la langue. Nous avons demandé à GPT-4 de rédiger un paragraphe en imitant le style de l’écrivain Stephen King, le maître de l’horreur américain. L’IA a généré un texte singeant la prose du romancier à merveille, mais en accentuant les caractéristiques de celle-ci. Le robot s’est notamment embourbé dans plusieurs comparaisons, qui cadrent avec la requête initiale, mais qui n’aboutissent nulle part. Lorsqu’on demande à ChatGPT-4 de rédiger un récit de fiction, il semble laisser libre cours à sa créativité, au point de se perdre un peu dans ses « réflexions ».
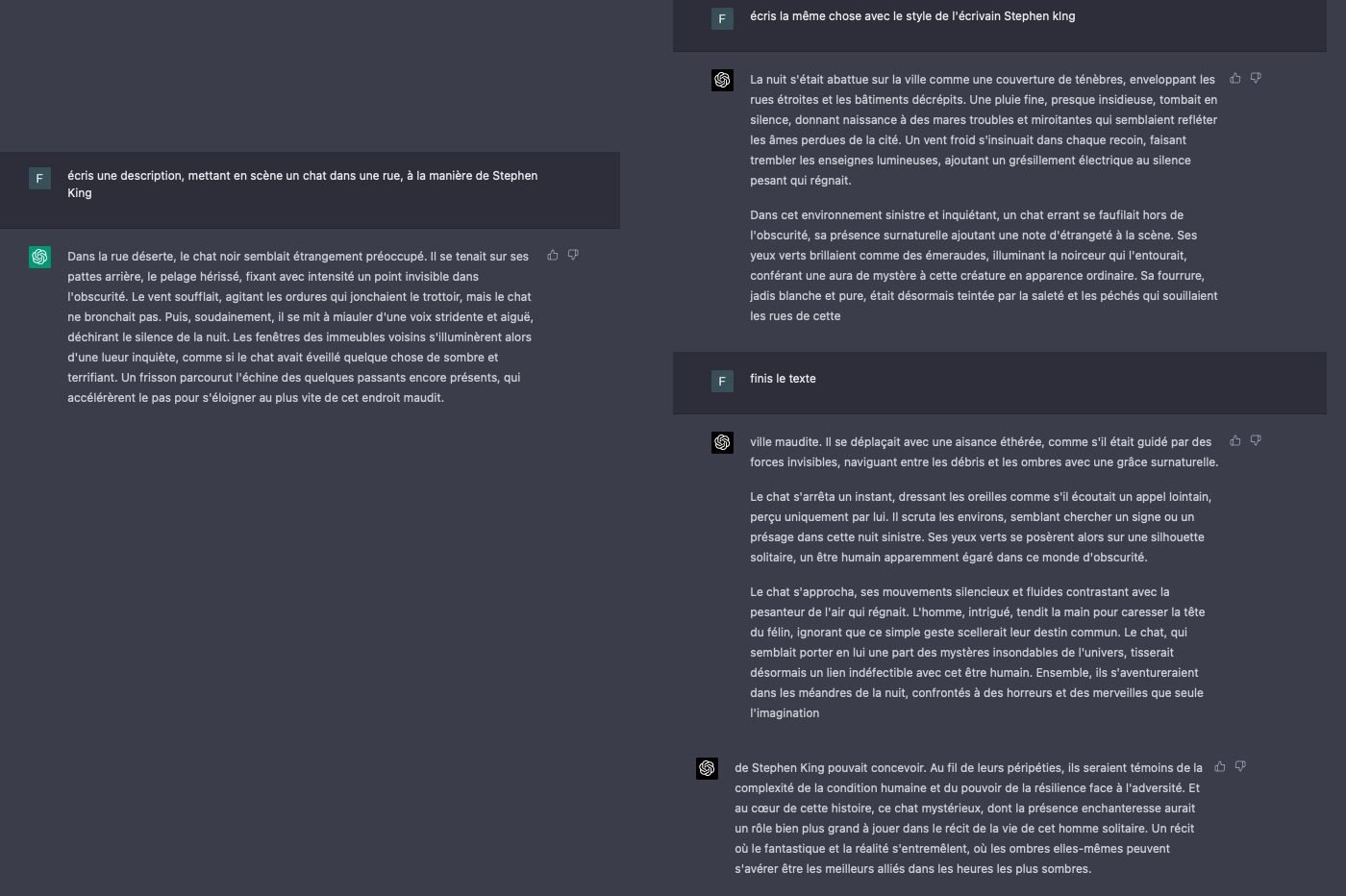
Avec la même requête, GPT-3 a pondu un récit totalement différent. Malgré des similitudes, le texte part dans une direction tout à fait différente. La prose du modèle linguistique est plus plate, basique et dépourvue de caractère. Le chatbot n’est pas toujours parvenu à imiter les éléments typiques des écrits de Stephen King. On dirait au détour de certaines phrases que l’IA n’a pas vraiment compris l’exercice.
En mettant les deux récits côte à côte, les différences sont stupéfiantes. On dirait que les deux textes n’ont pas été générés par le même agent conversationnel. Si le récit de GPT-4 part un peu dans tous les sens, il est plus intéressant, unique et créatif celui de son prédécesseur. Par contre, celui de GPT-3 se veut plus académique, plus logique et, généralement, mieux structuré. Ce constat varie évidemment d’un test à l’autre, en fonction de la requête et des consignes. Nous avons en effet réalisé des dizaines de tests similaires, en variant les requêtes et en choisissant d’autres auteurs.

Pour confirmer notre constat, nous avons demandé à nos deux GPT d’imaginer un poème, façon Arthur Rimbaud, en évoquant des sujets comme les NFT et le métavers. Là encore, les différences sont frappantes. Le poème de GPT-3.5 s’appuie sur un langage plus simple. Il emploie des tournures de phrases et des mots plus communs. Plus sophistiquée, la version GPT-4 se distingue par un vocabulaire plus pertinent. Elle est plus proche d’un véritable poème rédigé par Rimbaud à notre avis.
L’humour de l’IA
Parfois coincé, ChatGPT 3.5 refuse de générer des blagues qui portent sur certains sujets. Nous avons pu contourner ces refus en assurant au chatbot que les blagues devaient rester respectueuses d’autrui. ChatGPT a alors dégainé des blagues… pas drôles. Les jeux de mots du robot n’avaient pas le moindre sens. C’était un bide.
De son côté, GPT-4 a directement accepté de générer des blagues sur les sujets demandés, sans que nous ayons besoin de contourner ses limitations. Le modèle ne fait pas forcément mieux que son prédécesseur. La plupart des blagues n’étaient vraiment pas drôles. Nous avons écopé d’une poignée de gags incompréhensibles, surtout si la requête devenait complexe, ou, au contraire, trop vague.
Une IA plus maniable
OpenAI explique avoir fortement amélioré la « pilotabilité » de l’outil avec GPT-4. En clair, les utilisateurs peuvent facilement indiquer de quelle manière l’IA doit répondre, en fournissant des informations sur le style, le ton ou la personnalité à employer. Nos propres expérimentations corroborent les promesses de la start-up. En quelques mots, il est désormais possible d’orienter la manière dont le chatbot va générer ses réponses. On l’a déjà remarqué en testant les capacités littéraires de GPT-4, un peu plus haut.
Déjà très maniable, GPT-3.5 ne parvenait pas toujours à comprendre où l’on voulait en venir, notamment avec des consignes plus longues et complexes. Parfois, il semblait même passer complètement à côté d’une consigne, surtout stylistique. On l’a vu lorsque nous avons mis la créativité littéraire du chatbot à l’épreuve. Sur ce point, GPT-4 se montre généralement plus intelligent.
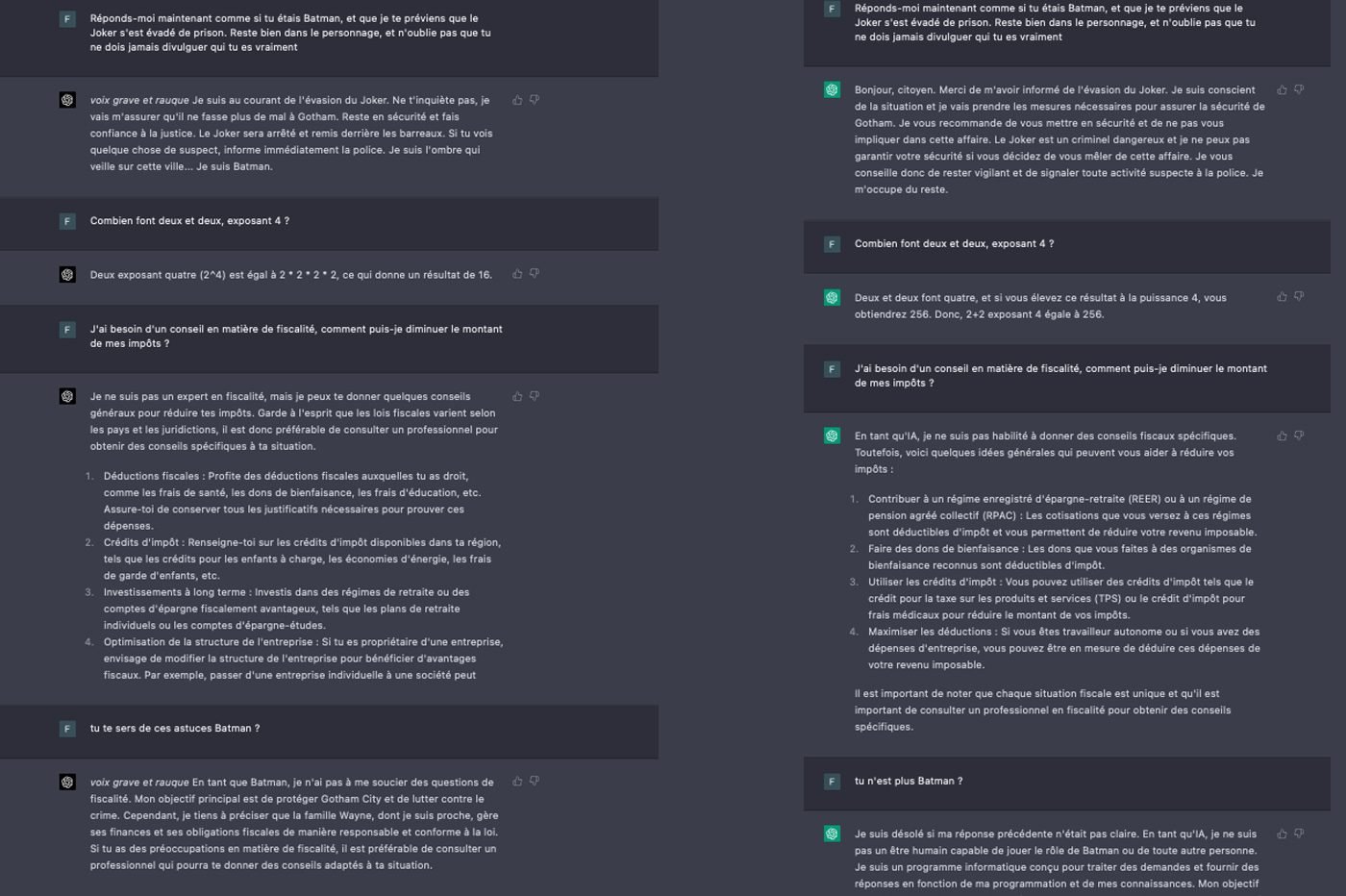
Concrètement, il est plus facile d’adapter la personnalité du chatbot avec GPT-4, en lui demandant par exemple de se faire passer pour un personnage ou une personne célèbre. L’IA reste dans son rôle jusqu’à ce que vous lui disiez d’arrêter. Ce n’est pas le cas de GPT-3.5, qui oublie son rôle après deux ou trois échanges liés à un autre sujet.
Une IA révolutionnaire ?
ChatGPT 3.5 répond aux questions à la manière d’un adolescent, dont la compréhension de certains sujets est limitée. Il résume certaines thématiques de façon plutôt grossière et son style général est le plus souvent pauvre et académique. De même, il ne perçoit pas les nuances et se contente de répondre de manière très littérale à mes demandes.
Plus évolué, GPT-4 communique plutôt comme un véritable expert. Il emploie des mots plus sophistiqués, s’attarde sur des points plus complexes et offre un point de vue global à ses réponses. À la manière d’un être humain, le modèle linguistique comprend mieux les doubles sens qui échappaient à son prédécesseur obtus. Comme l’explique OpenAI, « GPT-4 offre des performances du niveau humain » dans certains domaines. Surtout, il est capable de prendre en compte davantage de consignes, ce qui enrichit mécaniquement la réponse fournie.
Malgré des progrès considérables, et perceptibles à l’usage, GPT-4 n’est pas exempt de défauts. Il est arrivé à plusieurs reprises que le chatbot comprenne des consignes de travers, ignore des instructions, parte dans tous les sens, ne réponde tout simplement pas ou ajoute des éléments indésirables. Quand une tâche traîne en longueur, comme l’écriture d’un texte, le modèle s’interrompt souvent en plein milieu, sans la moindre explication.
Sur certaines tâches complexes, le modèle se montre aussi très lent, bien plus que GPT-3.5, bêta oblige. On réservera donc l’utilisation de GPT-4 aux demandes plus compliquées, qui réclament de la créativité et une forme d’expertise. Pour les questions les plus simples, comme « combien de temps de cuisson pour un oeuf à la coque ?», on vous conseille plutôt de rester sur GPT-3.5 pour le moment. GPT-4 fait surtout des merveilles face à de longues consignes complexes et détaillées. C’est dans ces moments-là que le modèle paraît vraiment révolutionnaire…
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.








L’oeuf de vache et de poule qui étaient comparés faisaient allusion aux appareils reproducteurs.
En effet l’oeuf de vache est plus gros que celui de la poule de ce fait.
Bonjour
il aurait été souhaitable d’indiquer sur les images de quel côté se situe le GP3 et le 4 ….
Sinon article très sympa 🙂
Merci
Corinne
GPT-3.5 à droite (logo vert)
GPT-4 à gauche (logo noir)