

Les méthodes traditionnelles de rendu 3D comme la rastérisation ou le ray-tracing, même lorsqu’elles sont accélérées par les cartes graphiques de dernières générations, atteignent actuellement leurs limites face à la complexité croissante des scènes à afficher et aux effets visuels de plus en plus sophistiqués que l’on trouve dans les jeux les plus récents. L’industrie du jeu vidéo cherche donc de nouvelles méthodes pour offrir des expériences toujours plus agréables et fluides, d’où l’arrivée ces dernières années de techniques utilisant l’intelligence artificielle, avec comme principale idée de générer une frame intermédiaire à partir de deux images successives ; c’est ce que propose la Frame Generation du DLSS 3 de NVIDIA et du FSR 3 d’AMD.
Mais ces méthodes d’interpolation présentent un inconvénient majeur : elles ajoutent de la latence. C’est pourquoi elles sont généralement associées à d’autres techniques destinées à maintenir une latence aussi faible que possible, comme NVIDIA Reflex sur les GeForce RTX. Des chercheurs de chez Intel associés à l’Université de Californie à Santa Barbara présentent dans un papier de recherche une méthode alternative baptisée GFFE (G-buffer Free Frame Extrapolation), basée cette fois-ci sur l’extrapolation et n’introduisant a priori pas de latence supplémentaire.
A lire aussi : DLSS, FSR, XeSS : quelle technologie d’upscaling choisir ?
GFFE : des images extrapolées plutôt qu’interpolées
L’interpolation classique utilise des algorithmes d’apprentissage profond qui nécessitent à la fois des données présentes dans les images passées et futures. L’extrapolation de frames synthétise quant à elle de nouvelles images en se basant uniquement sur l’historique des images passées et leurs informations. Cela permet donc d’augmenter la fréquence d’images perçue tout en évitant les délais introduits par les méthodes d’interpolation du DLSS ou du FSR FG. L’absence de latence supplémentaire est un avantage indéniable pour les applications en temps réel comme les jeux.
La gestion des occlusions, soit les zones qui apparaissent dans l’image actuelle mais étaient cachées dans les images précédentes, ainsi que l’estimation précise du mouvement des objets et des ombrages restent les principaux problèmes que rencontrent les méthodes d’extrapolation de frames. C’est donc sur ces points que se concentrent les recherches actuelles : le GFFE utilise plusieurs techniques innovantes pour surmonter ces obstacles, tout en garantissant des résultats visuels de haute qualité et une intégration aisée dans les moteurs de rendu existants.
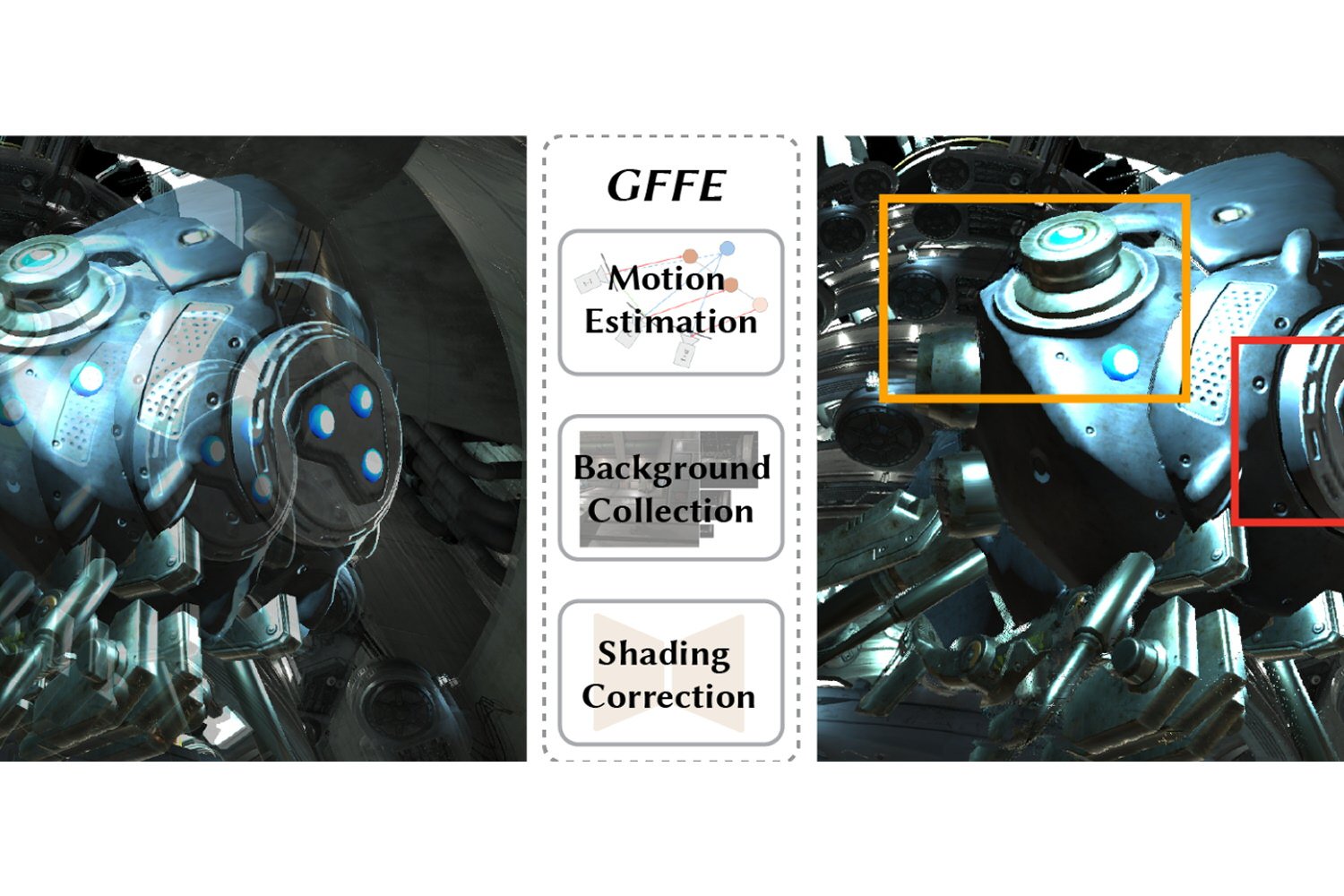
Gérer les trois types d’occlusions, sans G-Buffer
Les occlusions peuvent être de trois types : celles hors écran qui apparaissent lorsque la caméra se déplace et révèle des zones qui n’étaient pas visibles auparavant, les occlusions statiques dues à des objets fixes qui bloquent d’autres éléments de la scène, et les occlusions dynamiques causées par le mouvement d’objets mobiles. Ces zones qui ne sont pas présentes dans les images précédentes demandent donc des informations supplémentaires aux algorithmes d’extrapolation.
Les méthodes traditionnelles d’extrapolation utilisent souvent des “G-buffers” pour guider la génération des images : ce sont des informations géométriques et matérielles relatives à la scène, telles que la profondeur, les normales et les textures. Leur utilisation peut cependant s’avérer coûteuse en termes de performance et de mémoire, en particulier sur les appareils mobiles ou lors de rendu utilisant des pipelines spécifiques.
Le GFFE se distingue justement par sa capacité à effectuer de l’extrapolation de trames sans avoir besoin des G-buffers, d’où son nom. Au lieu de cela, il utilise l’historique des images précédentes pour estimer le mouvement des objets et gérer les différents types d’occlusion. Le fonctionnement de GFFE repose sur un cadre heuristique innovant et un réseau neuronal permettant d’analyser les mouvements des éléments dynamiques dans la scène.
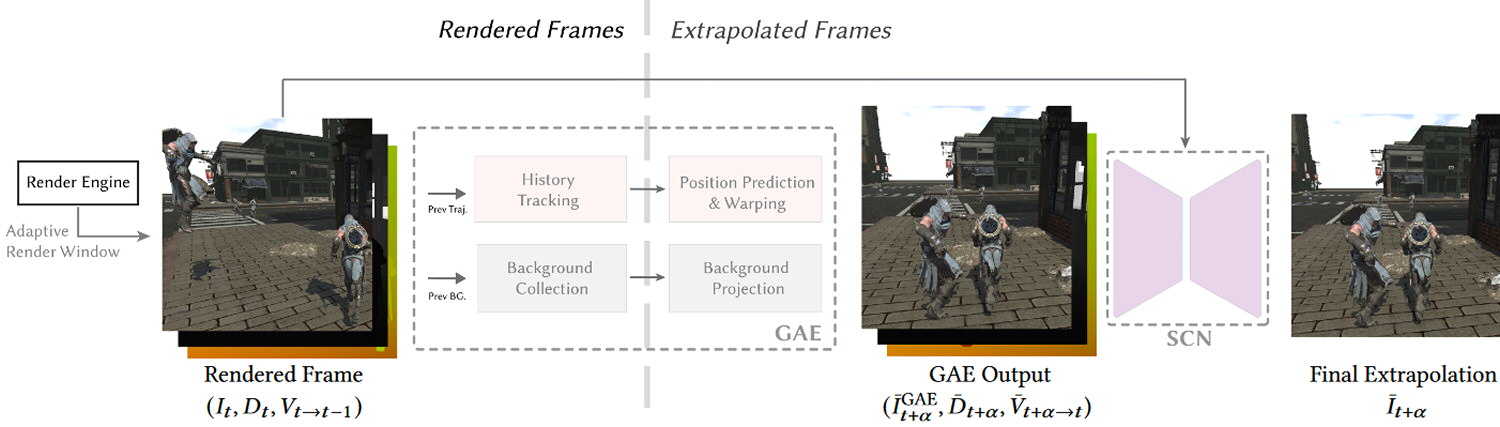
La méthode comprend plusieurs parties : un module d’estimation du mouvement qui suit la trajectoire des éléments dans l’espace 3D et estime leur position future, un module de collecte d’arrière-plan qui maintient des informations sur les zones qui étaient cachées dans les images précédentes, un module de fenêtre de rendu adaptative qui ajuste la zone de rendu en fonction des mouvements de caméra, et un réseau neuronal de correction de l’ombrage qui améliore la cohérence visuelle.
GFFE : implémentation et performances
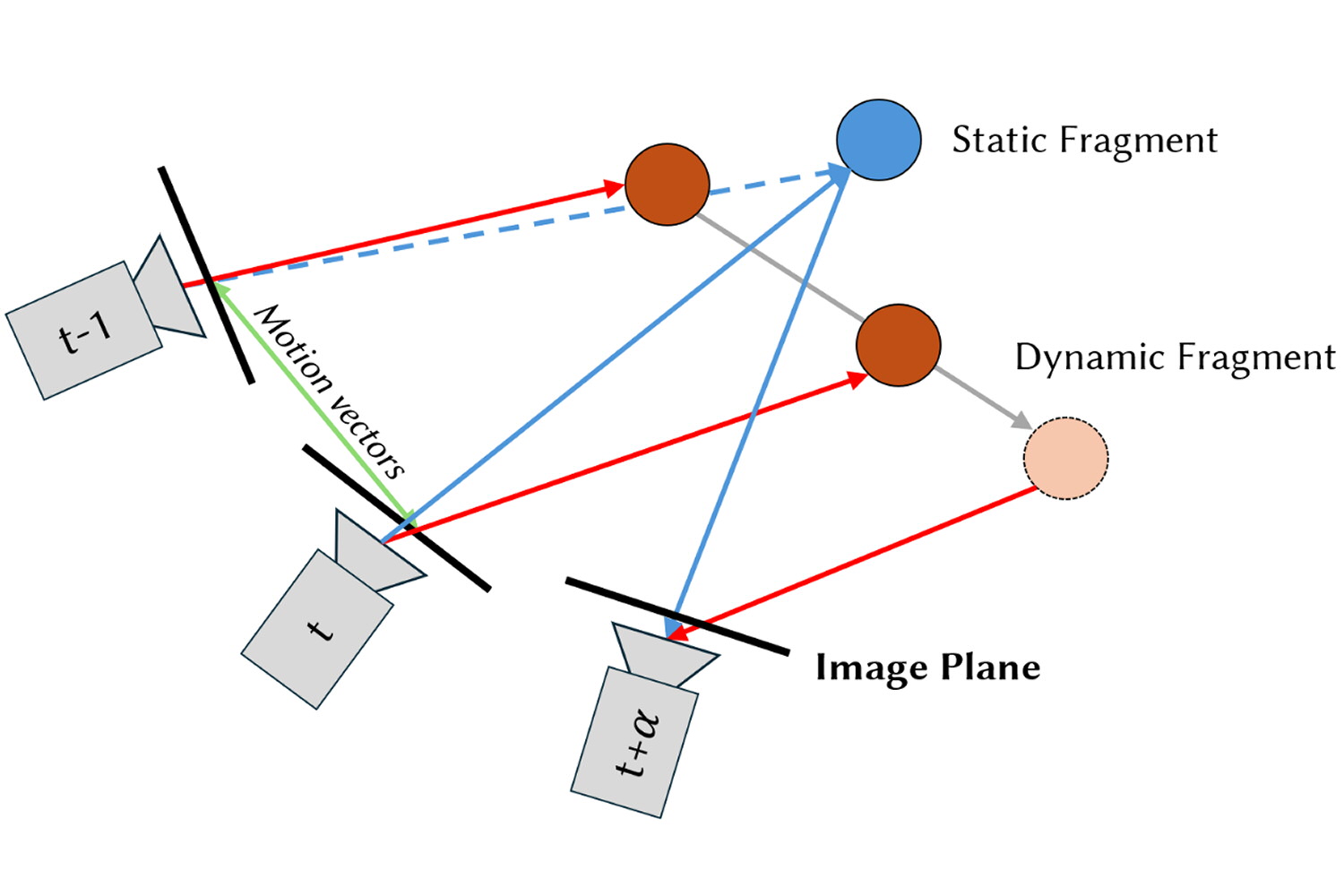
Plus précisément, la trajectoire de chaque élément de l’image dans l’espace 3D est calculée récursivement pour chaque image rendue, en utilisant les vecteurs de mouvement et les matrices de projection de la caméra. La position future de chaque élément est ensuite estimée à partir de sa trajectoire passée, en utilisant une approximation linéaire. Cette approche permet d’obtenir des estimations de mouvement plausibles tout en restant économe en ressources.
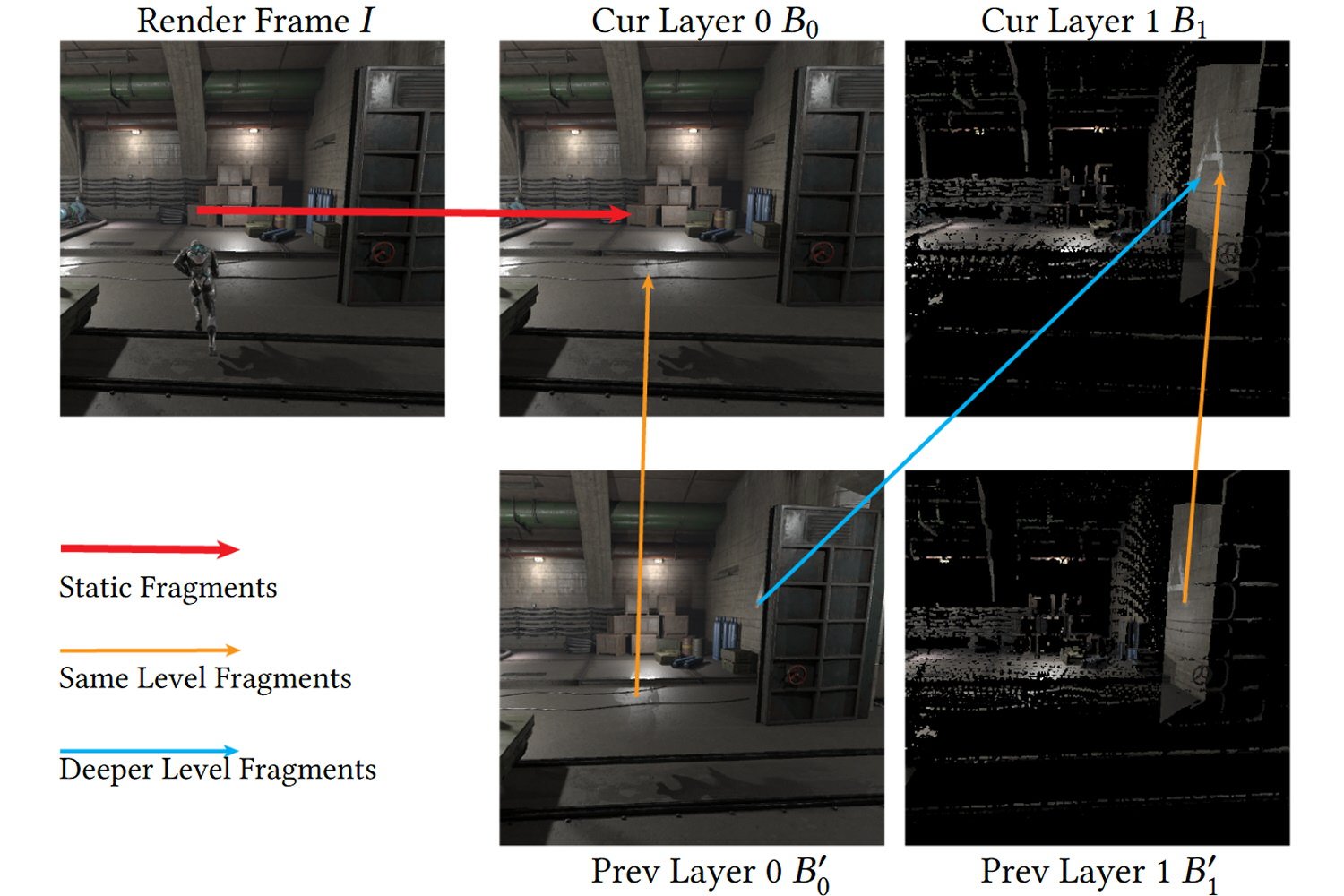
Pour gérer les occlusions, le GFFE utilise un système de collecte d’arrière-plan qui maintient plusieurs couches d’informations sur les éléments cachés. Ces couches sont mises à jour en fonction des images rendues, et leur contenu est projeté sur les nouvelles images afin de combler les zones qui n’étaient pas visibles dans les images précédentes. La fenêtre de rendu adaptative gère de son coté les occlusions hors écran, en agrandissant dynamiquement la zone de rendu en fonction du mouvement de la caméra.

Le réseau neuronal de correction d’ombrage est enfin utilisé pour améliorer la qualité visuelle des images extrapolées, en corrigeant en particulier les ombres et les reflets qui peuvent ne pas suivre les mêmes trajectoires que les objets. Ce réseau neuronal se base sur des masques de focus pour cibler les zones qui nécessitent une correction, ce qui permet de préserver les détails nets dans le reste de l’image.
En pratique, les résultats obtenus sont comparables, voire meilleurs, que ceux des méthodes d’interpolation ou d’extrapolation basées sur les G-buffers. GFFE se distingue par sa robustesse et sa généralisation, étant capable de fournir des résultats plausibles dans une variété de scènes, même celles qui n’ont pas été utilisées pendant l’entraînement. Cerise sur le gâteau, le GFFE est plus efficace et plus facile à intégrer dans les moteurs de rendu 3D en temps réel.
Une méthode pas encore parfaite
La méthode GFFE n’est toutefois pas parfaite et présente encore quelques limitations. Elle peut par exemple échouer dans le cas d’occlusions qui n’ont jamais été visibles dans l’historique des images, ou en présence d’effets visuels qui ne sont pas basés sur la profondeur, tels que des particules ou des interfaces de jeu. Les corrections d’ombrage et de reflets peuvent parfois être imparfaites en raison du manque d’information provenant des images futures.
Les travaux actuels des chercheurs de chez Intel représentent tout de même une avancée significative dans le domaine : leur solution se montre d’ores et déjà efficace pour améliorer les performances graphiques sans compromettre la qualité visuelle ni – surtout – introduire de latence supplémentaire. De quoi ouvrir de nouvelles perspectives pour les applications mobiles, le cloud gaming et plus globalement les plateformes où les ressources sont limitées ou spécifiques.
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.
Source : University of California, Intel












