

Il n’y a pas de fumée sans feu. Si AMD a été choisi pour propulser les deux supercalculateurs les plus puissants du monde, c’est autant pour une question de rapport qualité/prix que pour des choix technologiques pertinents pour les usages cibles.

Après que le département américain de l’énergie a annoncé, hier, avoir retenu des CPU et GPU AMD pour leur « El Capitan » – un monstre qui affiche 2 exaflops au compteur – on en sait aujourd’hui un peu plus sur les éléments techniques qui ont motivé la décision.
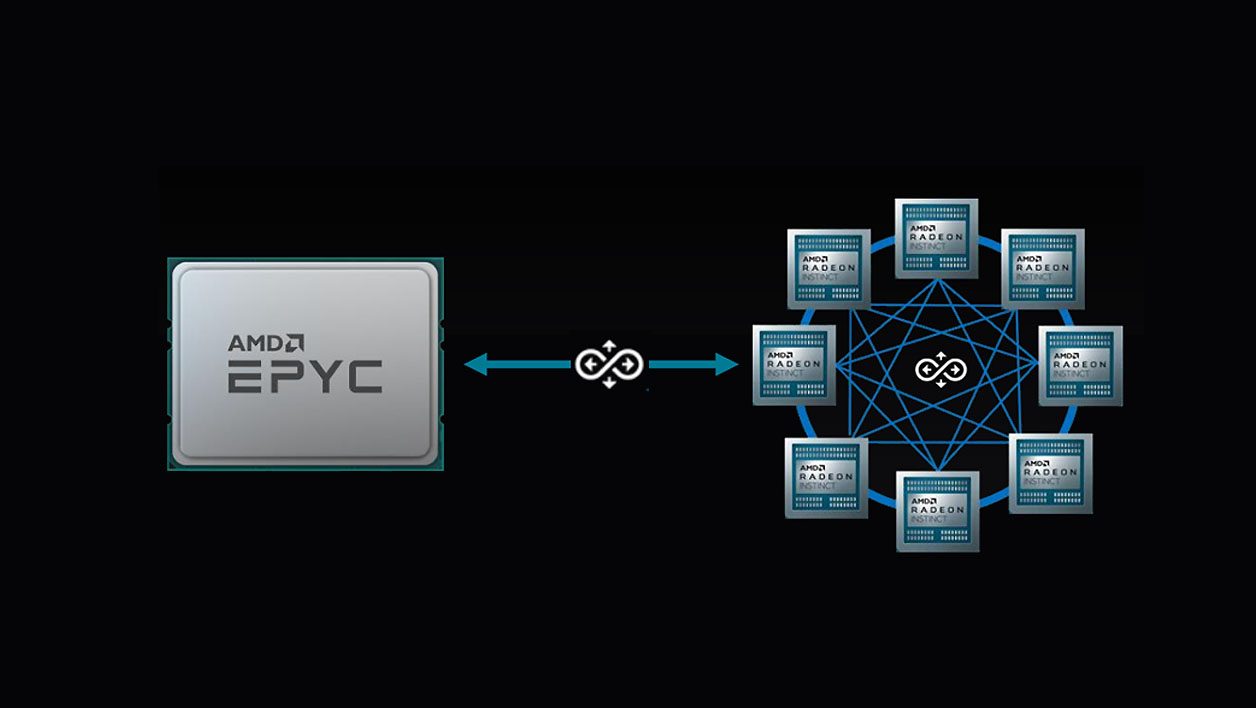
Infinity Architecture : accélérer la communication entre les puces

La première innovation tient non pas dans le nombre de cœurs ou les fréquences, mais dans la communication. Plus précisément dans la communication des composants entre eux, une piste qu’explore déjà la première génération de puces pour serveur EPYC.

À l’heure actuelle, deux CPU EPYC peuvent être « couplés » par le protocole d’interconnexion Infinity Fabric et ainsi adresser jusqu’à quatre GPU chacun. Problème : chaque GPU est perçu comme une entité unique, sans partage d’information entre eux. La prochaine et deuxième génération du protocole prend le nom de « Infinity Architecture », et permettra à chaque CPU d’adresser chacun quatre GPU qui non seulement pourront communiquer avec le CPU, mais aussi échanger des données entre eux. De quoi éviter au système de perdre trop de temps à faire circuler les informations d’un GPU à l’autre.
Mais c’est la troisième génération du protocole appelée « Infinity Architecture » qui est la plus importante et qui sera au cœur des performances du supercalculateur El Capitan. Un système où jusqu’à huit GPU sont interconnectés entre eux pour former un « super GPU ». Plus besoin d’adresser séparément chaque processeur graphique, le couple de processeurs EPYC s’adressera aux GPU de manière indiscriminée.
Les GPU se chargeront de répartir les informations et la charge de travail entre eux. De quoi faciliter le travail des programmeurs et, théoriquement, améliorer les performances.

Plus fort encore, l’Infinity Architecture Gen 3 permettra d’unifier la mémoire entre les CPU et les GPU, mais AMD n’a pas donné de détails techniques sur le fonctionnement de sa solution.
L’entreprise a cependant communiqué sur une partie du « secret » d’une communication si rapide entre les puces. Elle tient en autres à sa future technologie de packaging X3D. AMD sera en effet capable d’empiler de la mémoire ultra rapide sur plusieurs couches. La promesse est une multiplication par dix de la bande passante entre les cœurs de calcul et la mémoire.
CDNA, des GPU dédiés aux calculs

L’autre innovation d’AMD est la création d’une nouvelle ligne de GPU professionnels basés sur une architecture appelée CDNA. Au contraire de ses puces RDNA (Radeon DNA) dont l’usage premier est graphique, qu’il s’agisse de cartes de jeux ou de cartes de rendu 3D professionnelles, les puces CDNA font l’impasse sur tout ce qui touche à l’affichage et sont optimisées pour le calcul.
Car aussi puissantes soient-elles, les cartes actuelles Radeon Instinct dérivent en effet de ces puces dédiées aux jeux vidéo. Elles intègrent donc des éléments – gestion des écrans, des shaders, etc. – qui n’ont aucun intérêt pour les calculs intensifs ou l’apprentissage profond des IA.
Débarrassées de ces portions inutiles, les futures puces CDNA disposeront de plus d’unités de calcul « utiles » et d’une architecture aux petits oignons pour le calcul hautement parallélisé.
De quoi bousculer Nvidia et Intel dans les centres de données ? Premier élément de réponse à partir de 2021 pour la livraison du supercalculateur Frontier et en 2023 pour la validation de l’échelon final de la technologie Infinity Architecture avec l’arrivée d’El Capitan.
Mais une chose est sûre : le roi des GPU qu’est Nvidia et l’empereur des CPU Intel (qui développe ses propres GPU grand public comme professionnels) ne vont pas rester assis les bras croisés…
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.












