


Le SLM d’AMD
À l’instar d’autres géants du secteur, AMD s’est lancée dans le SLM (Small Language Model, petit modèle de langage) avec son modèle open-source AMD-135M. L’entreprise l’avait longuement présenté dans un blog technique publié le 17 septembre dernier ; elle l’expose désormais à travers un article plus grand public. L’AMD-135M est également disponible via HuggingFace et GitHub.
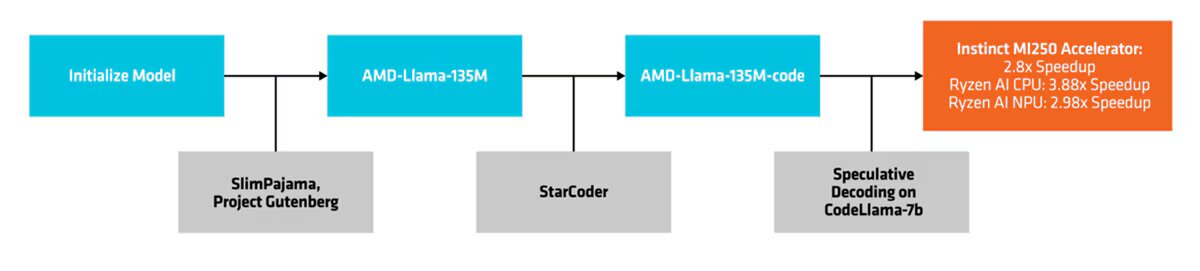
Ce petit modèle de langage appartient à la famille Llama (il se base sur l’architecture LLaMA2 précisément). Il se décline en deux versions : AMD-Llama-135M et AMD-Llama-135M-code.
Tous deux misent sur le décodage spéculatif. Le principe de base de cette approche ? Utiliser un petit modèle préliminaire pour générer un ensemble de tokens potentiels, lesquels sont ensuite vérifiés par un modèle cible plus large.
L’AMD-135M a été entraîné sur 670 milliards de tokens à l’aide d’accélérateurs AMD Instinct MI250. Avec quatre nœuds de MI250 (chaque nœud possède quatre accélérateurs MI250), la procédure a duré six jours. AMD précise avoir utilisé les ensembles de données SlimPajama et Project Gutenberg (une bibliothèque de plus de 70 000 livres électroniques gratuits) pour pré-entraîner ce modèle 135M.
La variante AMD-Llama-135M-code a été affiné avec 20 milliards de tokens spécifiquement axés sur le codage. Il a fallu quatre jours complets pour peaufiner ce code sur quatre accélérateurs MI250.
SLM vs LLM
Nous avions explicité les avantages des SLM par rapport aux LLM à l’occasion du déploiement de Phi-3 Mini par Microsoft. Si vous avez besoin de quelques révisions, l’article initial consacré à l’AMD-135M apporte quelques éclairages intéressants. Dans tous les cas, pour approfondir ce sujet, n’hésitez pas consulter notre dossier définissant les modèles de langage pour IA.
Le document rappelle qu’en dépit de l’importance des LLM, « il existe des arguments convaincants en faveur des modèles de langage plus petits (SLM), qui offrent une solution pratique permettant d’équilibrer les performances et les contraintes opérationnelles ». Vous l’aurez compris avec ce qui précède, tandis que l’entraînement des LLM nécessite souvent une vaste gamme de GPU haut de gamme, les SLM offrent une solution alternative. De plus, la publication souligne que « s’il existe un moyen d’obtenir un LLM bien entraîné, il est souvent difficile de l’exécuter efficacement sur un appareil client avec des ressources informatiques très limitées ». D’ailleurs, AMD met en avant les bénéfices de l’inférence avec décodage spéculatif pour son SLM AMD-135M non seulement avec des accélérateurs Instinct MI250, mais aussi avec du matériel grand public, en l’occurrence avec le Ryzen 9 PRO 7940HS.
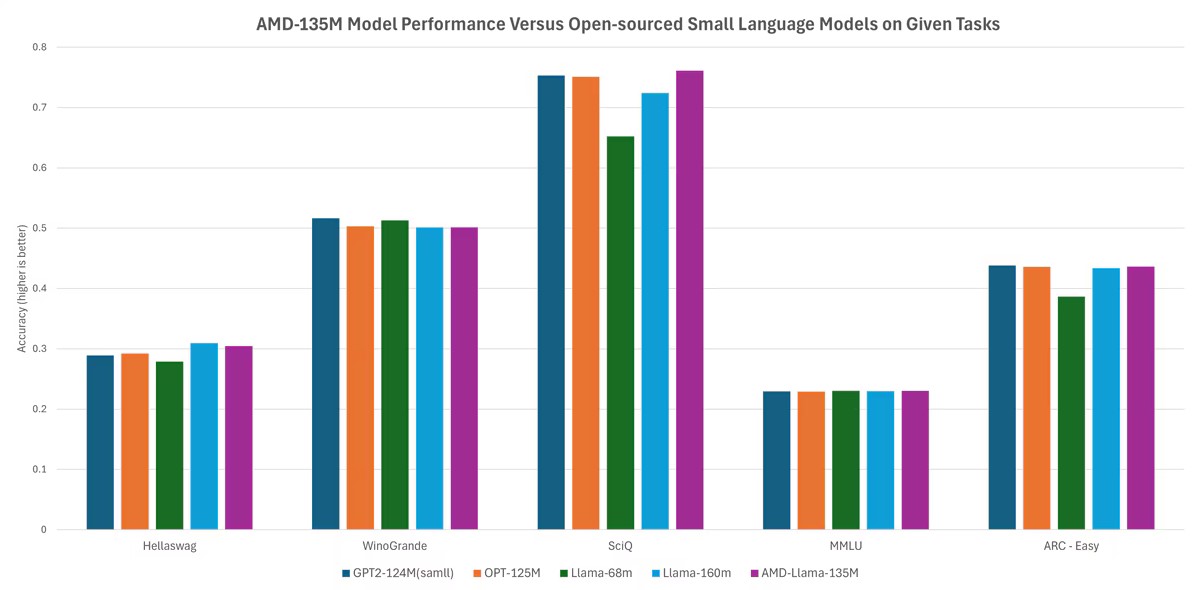
Enfin, sans vous assommer de chiffres, AMD revendique des « performances comparables à celles des modèles les plus répandus sur le marché » (Llama-68M et Llama-160M ; GPT2-124M ; OPT-125M) pour son modèle AMD-135M dans Hellaswag, WinoGrande, SciQ, MMLU et ARC-Easy.
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.
Source : AMD











